NetApp and Cisco have a long and well-regarded partnership, with the joint FlexPod offering being the best known and marketed. The collaboration between the companies often extends in less well-advertised but no less interesting ways. One that has been a personal highlight for me is NetApp providing the storage for the infrastructure that runs the Network Operations Center (NOC) for five of the last Cisco Live events in the US and Europe. This includes acting as a member of the NOC team both prior to the show and during the event: NetApp personnel arrive with Cisco staff the week before the show begins to setup the environment, and ensure that everything runs smoothly and non-disruptively for the attendees.
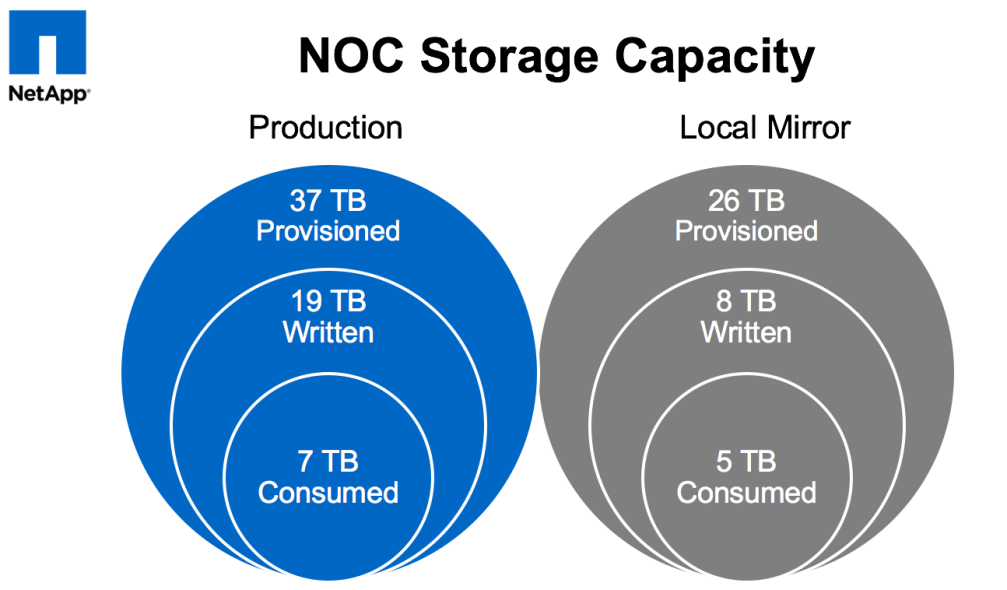
The core infrastructure – comprised of FlexPods as we leverage Cisco Nexus switches and UCS servers in conjunction with our NetApp FAS storage – has been relatively small: less than 20 servers and and less than 50TB of provisioned storage. From a sheer numbers perspective, the majority of the equipment managed by the NOC team is at the edge: 500+ switches and 600-900 wireless access points. (Any and all numbers vary by year and by location. YMMV.) What is common to all of this infrastructure: it must be able to be stood up quickly once on site, it must perform well (as the large number of attendees do their best to test the limits of the environment – whether accidentally or deliberately), and, most importantly, it must be highly reliable and can not go down.
When we started it was with classic 7-mode systems: a mid-range FAS3200 series HA pair with several shelves of SAS drives for production on-site at the event, and a secondary FAS2200 series HA pair for DR and co-located services. Both systems worked well supporting the virtual infrastructure powering the event.

In 2014 we upgraded the production hardware to a FAS8000 series running clustered Data ONTAP along with some new disk shelves. Flash Cache was also included to assist with things like VDI – that year the NOC provided virtual desktops for many of the labs that were being performed at the show. The system continued to work well with zero downtime or performance issues, and providing significant storage efficiencies. We had so much extra space due to NetApp dedupe, thin provisioning, etc. that we even mirrored most data locally between the controllers to provide yet-another level of redundancy (belts, suspenders, and safety pins).
Now we’ve upgraded again: starting with this week’s Cisco Live Europe show in Berlin, the Cisco Live NOC runs on an AFF MetroCluster!
What’s AFF? AFF stands for “All-Flash FAS” – this is the flash-only version of NetApp’s storage controllers that run clustered Data ONTAP: specifically optimized for low-latency flash performance. While sharing the same OS with our traditional FAS storage arrays enables customers to get all of the benefits of our rich family of integrated data management services, there are now software optimizations for flash that are only enabled in the AFF series, and those optimizations are already showing significant improvements across minor version releases (8.3.0 -> 8.3.1 -> 8.3.2).
Why AFF? …. why not? During last year’s Cisco Live US we found that the IO load on the existing back-end disks was approaching the point at which contention and undesirable latency would start to be introduced. While the controllers themselves could produce more performance, we would have needed to add more disk shelves in order to provide any significantly increased amount of IOPS. Because we were not capacity bound, it made much more sense to instead replace the SAS drives with SSDs for the best performance possible and the most room for growth (in IO). We could have kept the existing FAS controllers to use with new SSDs – many of our FAS customers have been using hybrid or all-SSD configurations for years – but there was no good reason to not also take advantage of the performance improvements specific to the AFF line of controllers.
What’s MetroCluster? It’s an implementation of NetApp’s FAS (or AFF) storage controllers that provides high availability and disaster recovery across physical sites with zero data loss (zero RPO – recovery point objective) and minimal downtime (low to near-zero RTO – recovery time objective). In order to achieve zero data loss, of course, you must be performing synchronous writes to two different sets of physical media, and for disaster recovery those sets must be in different physical locations. Because the speed of light is a real limit, in order to perform synchronous writes those two locations need to be relatively near each other so that the round-trip time latencies are acceptable (the controller can’t acknowledge a write operation back to the host until that write is committed at the remote site, not just the local site). With a maximum supported distance of 200km (for now) you get a cluster that can operate across a “metropolitan” area. Customers have been using MetroCluster to protect their most mission critical data in this fashion for 10 years now.
So why MetroCluster? As I noted above, we had been replicating most of the Cisco Live data locally for an extra level of protection anyway, but, more importantly, for Cisco Live Europe a different need arose: active/active storage across two physical locations. At prior shows, the completely redundant FlexPod environments (as shown in the diagram above) had been located proximal to each other. For the 2016 show the goal was to take advantage of the building layouts at the new location (City Cube in Berlin) to provide even more redundancy by placing half of the infrastructure in each of two different buildings (one FlexPod per building). Very early in these planning stages it became obvious that using an AFF MetroCluster for Cisco Live was simply the right thing to do.
We’re now a few days into Cisco Live Europe 2016, and things are going well. On Friday we’ll be having the traditional NOC panel during the last session slot of the show where we’ll discuss the build-out, how the entire infrastructure (wired, wireless, WAN, datacenter, etc.) has performed, lessons learned, and any interesting statistics. I’ll also post a follow-up blog about my experiences at the show.
For now, here’s a pic of one of the FlexPods (one half of the core datacenter infrastructure) as we were getting it plugged in on the first day. This was before it was powered on – hence the lack of blinkenlights.

